






AI infra choices are now a P&L decision. If you’re shipping LLM features at scale, every token, millisecond, and vendor choice shows up in your margins.
Two poles dominate this decision:
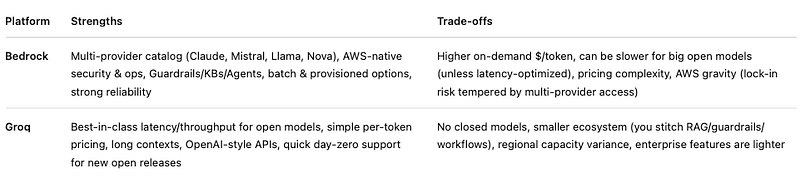
- Amazon Bedrock: enterprise-grade, multi-model, deeply integrated with AWS.
- Groq: custom LPU hardware, speed-first for open models at aggressive per-token pricing.
This post compares them with current (2025) pricing patterns, performance realities, and practical playbooks you can ship today.
TL;DR
- Latency & Throughput: Groq routinely leads on open models (Llama/Mixtral/Gemma): lower time-to-first-token and higher tokens/sec. Bedrock’s latency-optimized options narrow the gap for select models (e.g., Claude 3.5 Haiku), and Bedrock tends to win on multi-model reliability.
- Pricing: Bedrock charges per token and varies by model. Example ballparks: Mistral 7B ~ $0.00015 in / $0.00020 out per 1k tokens; Claude Instant ~ $0.0008 in / $0.0024 out per 1k; Llama-2 70B ~ $0.00195 in / $0.00256 out per 1k. Batch can be ~50% off; provisioned throughput is available (e.g., Claude Instant ~ $44/hr with no commitment).
- Groq uses model-specific, pay-as-you-go rates. Example: GPT-OSS 120B ~ $0.15/M input & $0.75/M output. Expect tiers (Free/Dev/Enterprise) and different rates across models.
Where each shines:
- Groq for low-latency, high-throughput open models and long contexts (e.g., Qwen up to ~131k).
- Bedrock for enterprise controls, multi-provider access (Claude, Mistral, Meta, Amazon Nova), guardrails, knowledge bases, agents, and scaling inside AWS.
- Reality check: There’s no winner for every workload. Many teams save money and time with a hybrid: Groq on the hot path + Bedrock for proprietary models, governance, or fallback.
Quick Intros
AWS Bedrock: “The managed model mall”
One API to reach multiple providers (Anthropic, Mistral, Meta Llama, Amazon Nova, etc.), plus enterprise must-haves: IAM, VPCs, logging, Guardrails, Knowledge Bases, Agents/Flows, evaluations, and batch. It’s the fastest way to add LLMs without building your own scaffolding.
Groq: “The speed chip as a service”
A cloud built on custom LPUs (Language Processing Units) tuned for transformer inference. You bring open models (Llama/Mixtral/Gemma/Qwen/GPT-OSS), Groq serves them fast with simple per-token pricing. Fewer bells and whistles; more raw performance.
Pricing That Reflects 2025 Reality
Rule of thumb: Price varies by model and direction (input vs output). You won’t find one universal rate on either platform.
Bedrock (on-demand examples)
- Mistral 7B: ~$0.00015 input / $0.00020 output per 1k tokens
- Claude Instant: ~$0.0008 input / $0.0024 output per 1k
- Llama-2 70B: ~$0.00195 input / $0.00256 output per 1k
- Batch inference: often ~50% off on-demand for supported models.
- Provisioned throughput: e.g., Claude Instant ~ $44/hour (no commitment) to lock capacity + predictability.
- Extras to budget: Guardrails (text moderation) is metered (e.g., per 1k units), Knowledge Bases/vector storage, inter-region data transfer, etc.
Worked example (Bedrock):
1M tokens, Mistral 7B, 50/50 split
= 500k input × 0.00015/1k + 500k output × 0.00020/1k
= $0.075 + $0.10 = $0.175 (on-demand).
Batching can cut this ~in half. Provisioned can lower effective rate if you keep it busy.
Groq (model-specific, tiered)
- GPT-OSS 120B: ~$0.15/M input, $0.75/M output
- Other open models (Llama/Mixtral/Gemma/Qwen) have their o rates; Groq often undercuts general-purpose GPU clouds — especially on output.
- Batch/async lanes and prompt caching reduce costs further; speed can also lower total compute time and infra overhead.
Worked example (Groq):
1M tokens, open 70B-class model, 50/50 split
If we ballpark ~$0.10–$0.20/M input and $0.50–$0.90/M output (model/tier dependent), total often lands around $0.30–$0.55.
Your exact rate depends on model + tier + region.
Takeaway: For open models, Groq’s effective costs are frequently lower; Bedrock narrows the gap with batch, provisioned throughput, smaller models, and prompt caching.
Performance & Reliability
- Groq: Consistently lower TTFT (time-to-first-token) and higher tokens/sec on open models. Community and third-party tests put Groq’s Llama-class throughput far ahead of GPU stacks, with sub-100–300 ms TTFT typical for short prompts and hundreds of tokens/sec sustained on bigger outputs. Groq also supports very long contexts (e.g., Qwen ~131k).
- Bedrock: New latency-optimized modes (e.g., Claude 3.5 Haiku) have closed the gap for select models. In multi-model and multi-region setups, Bedrock tends to score higher on reliability, quota flexibility, and orchestration (Agents/Flows/KBs).
- Reality: Benchmarks vary by prompt length, context size, model, and region. Treat published TPS/MS numbers as ranges, not absolutes.
What’s New
- Groq: Day-zero support for new Llama-4 family releases; broader catalog of open models; deeper Hugging Face integrations; growing batch/caching options.
- Bedrock: Wider prompt caching (steep discounts on repeated prefixes), expanded batch support, more models (Anthropic, Mistral, Meta, Amazon Nova), and Guardrails pricing clarity for text/image safety.
Use Cases & Picks


How to Pay Less (and keep quality)
Bedrock optimization playbook
- Batch inference for offline jobs (often ~50% cheaper).
- Prompt prefix caching for repeated system prompts/history.
- Right-size models (e.g., Mistral 7B vs Llama-70B).
- Distill/compress big → small for production (2–4× savings).
- Provisioned throughput for steady traffic; keep it busy.
- Smart routing: cheap model first, escalate on confidence/complexity.
Groq optimization playbook
- Pick the smallest model that meets the SLA.
- Batch lanes + prompt caching where applicable.
- Exploit long context to reduce chunking and extra calls.
- For enterprise tiers, negotiate based on volume/latency SLOs.
Pros & Cons

A Simple Decision Tree
- Need Claude/closed models or heavy governance? → Bedrock
- Open-model app where latency = UX & margin? → Groq
- Both pressures exist? → Hybrid:
- Groq for 80–90% of traffic (fast/cheap)
- Bedrock as fallback (complex prompts, safety-critical, proprietary models)
- Add routing + confidence thresholds + batch for offline
FAQ
Q: When should I switch from Bedrock to Groq (or add it)?
A: When latency UX matters and open models meet your quality bar; or when your COGS per token starts to bite and batch/caching/provisioned aren’t enough.
Q: Can Bedrock match Groq pricing?
A: For many open-model workloads, not out-of-the-box. With batch + provisioned + smaller models + caching, you can meaningfully close the gap, especially for predictable traffic.
Q: Do I lose reliability with Groq?
A: You’ll likely gain speed and lower cost; reliability depends on region/capacity and your architecture. Many teams pair Groq with a Bedrock (or other) fallback.
Q: What about future-proofing?
A: Groq tends to support new open releases quickly (e.g., Llama-4). Bedrock keeps expanding vendors, features, and latency-optimized modes. Keep both options live; let routing decide.
Final Take
- Choose Bedrock for breadth, governance, and platform.
- Choose Groq for speed, open-model economics, and long contexts.
- Choose both when you care about all three: cost, latency, compliance.
If you run AI at scale, don’t marry a single provider. Put routing, observability, and cost controls in front, and treat inference like any other tier of your stack: benchmarked, multi-homed, and relentlessly optimized.








